
Ph.D. student @ Harbin Institute of Technology
Research Intern @ Microsoft Research Asia
[Resume]
# About Me
Hi there! I am a joint Ph.D. student of Harbin Institute of Technology and Microsoft Research Asia, supervised by Prof. Xiangzhan Yu and Dr. Ming Zhou. I obtained my B.S. degree at Harbin Institute of Technology, supervised by Prof. Wanxiang Che. Currently, I am working as a research intern at Natural Language Computing Group in MSRA, mentored by Dr. Yu Wu and Dr. Shujie Liu.
My current research focuses on language model pre-training for speech and audio processing, and I have developed several pre-trained models, including VALL-E, WavLM and BEATs, that have advanced the state of the art on various public benchmarks and contributed to the research field.
# Education & Experiences
Microsoft Research Asia May 2020 - Present
Research Intern in Natural Language Computing GroupHarbin Institute of Technology Aug 2019 - Present
Ph.D. Student in Research Center for Social Computing and Information RetrievalHarvard University Aug 2018 - May 2019
Research Intern in Data Systems LaboratoryNational Chiao Tung University Aug 2017 - Jan 2018
Exchange Student in Computer ScienceHarbin Institute of Technology Aug 2015 - Jun 2019
B.S. in Computer Science and Technology
# Selected Publications
→ Full list (1000+ citations) (*joint first author)
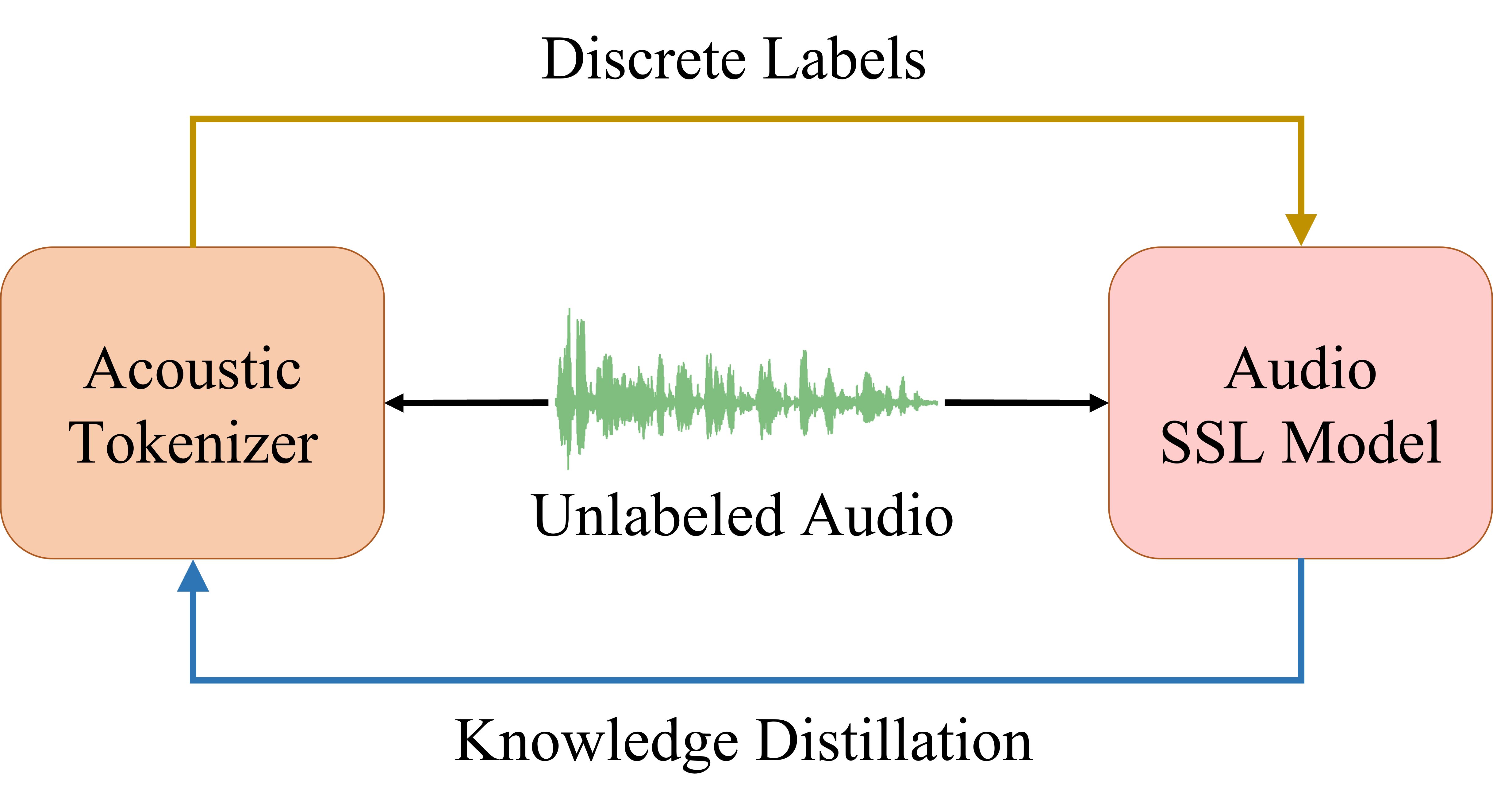
BEATs: Audio Pre-Training with Acoustic Tokenizers
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, Furu Wei
Ranks 1st in the AudioSet leaderboard.
Ranks 1st in the Balanced AudioSet leaderboard.
Ranks 1st in the ESC-50 leaderboard.
Powers the winner in DCASE 2023 Automated Audio Captioning Challenge.
Powers all the top 5 systems in DCASE 2023 Sound Event Detection Challenge.
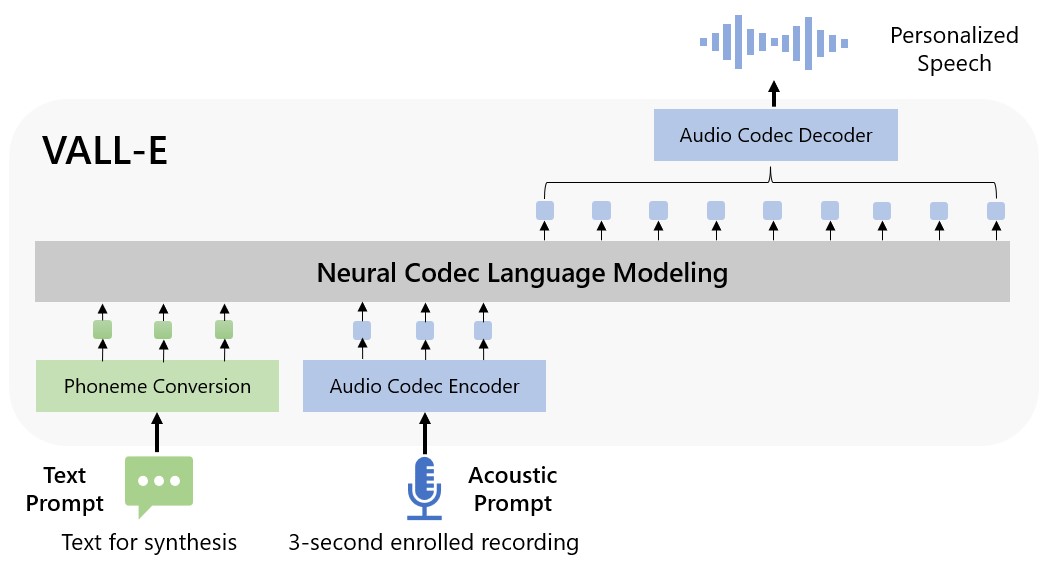
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang*, Sanyuan Chen*, Yu Wu*, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, Furu Wei
VALL-E can synthesize speech with anyone's voice from just 3 seconds of audio.
VALL-E X can help anyone speak a foreign language without an accent.
State-of-the-art zero-shot TTS system with in-context learning capabilities.
Wins the UNESCO Netexplo Innovation Award 2023 (top 10 out of over 3000).
[VALL-E paper] [VALL-E demo] [VALL-E X paper] [VALL-E X demo]
[Reddit Discussion] [Fox News] [Yahoo! News] [Ars Technica News]
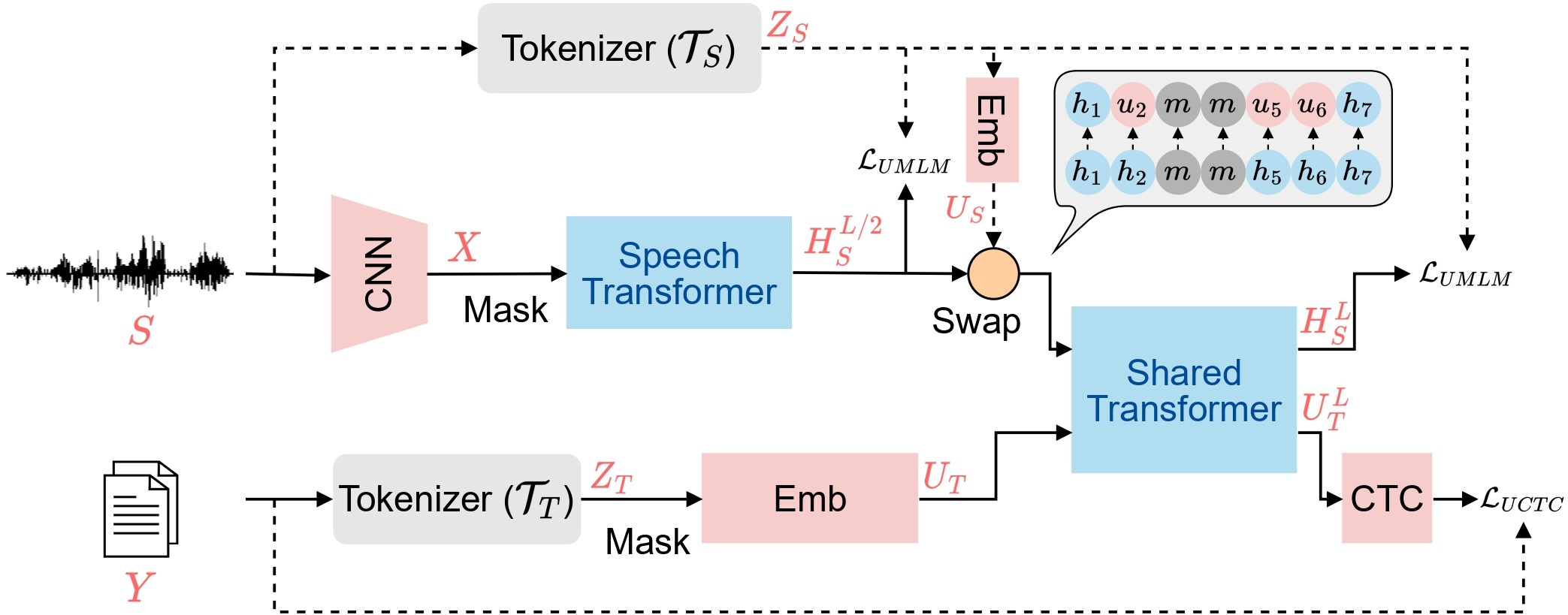
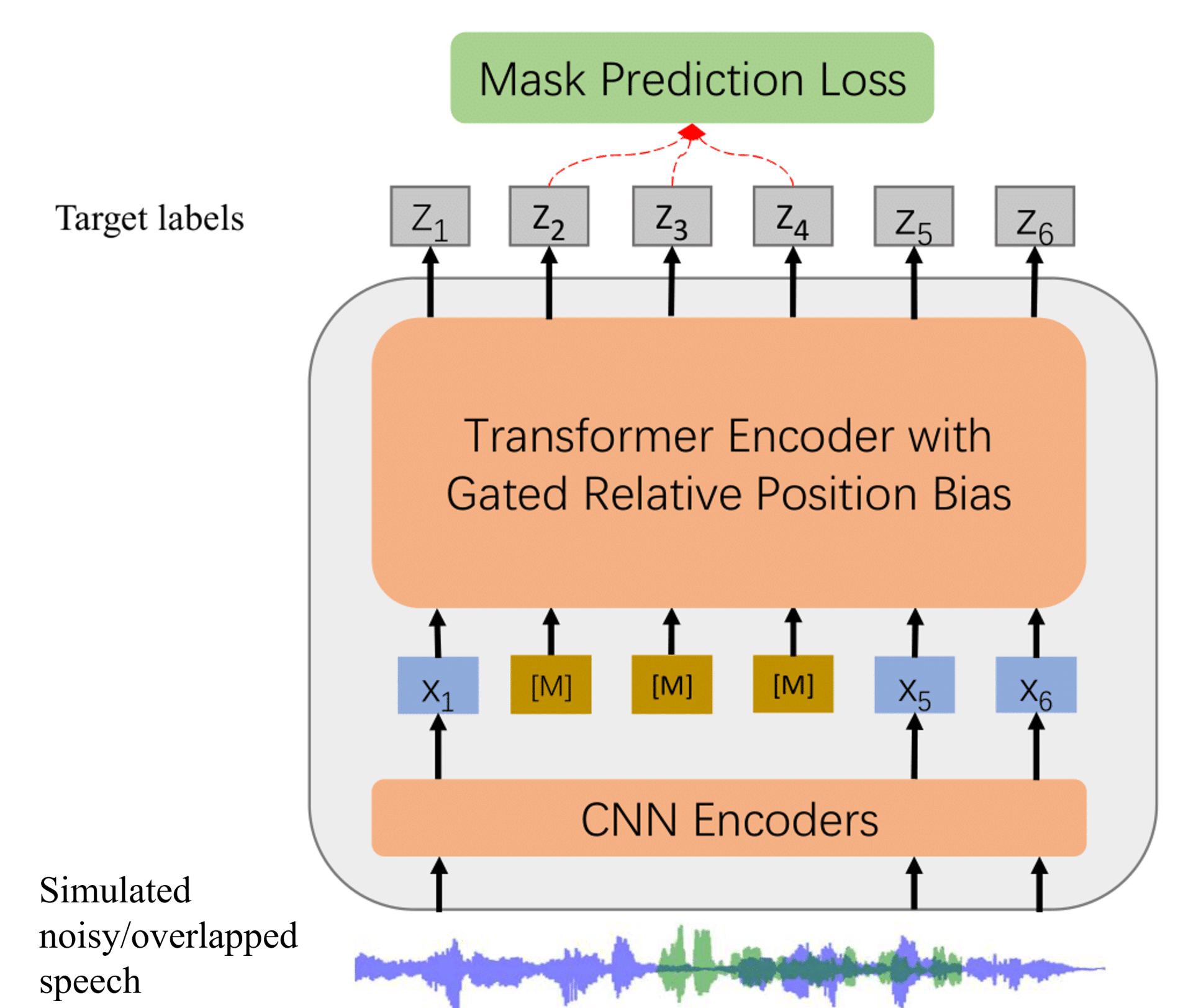
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, Furu Wei
Ranks 1st in the SUPERB leaderboard and SLT2022 SUPERB Challenge.
Ranks 1st on VoxSRC 2021 speaker verification permanent leaderboard.
Powers all the top 3 systems in VoxSRC 2022 speaker verification challenge.
[Accepted in J-STSP] [code] [demo] [blog] [HuggingFace API] [TorchAudio API]
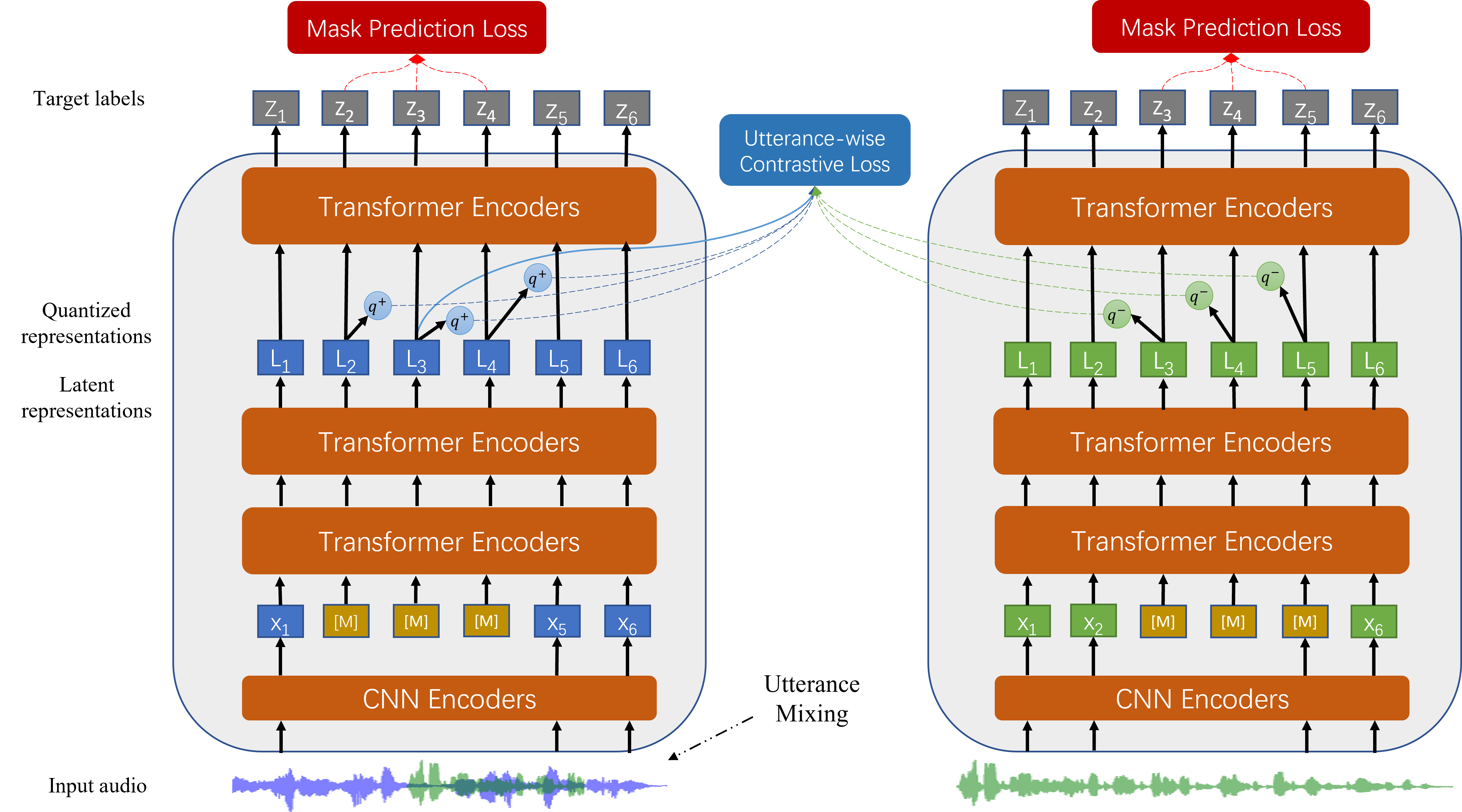
UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware Pre-Training
Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
[Accepted in ICASSP 2022] [code] [demo] [slides] [poster]
Why does Self-Supervised Learning for Speech Recognition Benefit Speaker Recognition?
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Zhuo Chen, Peidong Wang, Gang Liu, Jinyu Li, Jian Wu, Xiangzhan Yu, Furu Wei
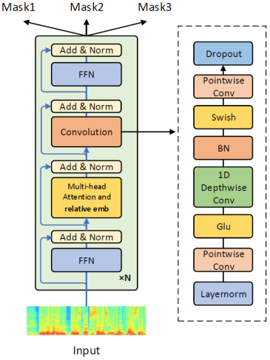
Continuous Speech Separation with Conformer
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, Furu Wei
Ranks 1st in the VoxCeleb Speaker Recognition Challenge 2020.
Shipped in the Microsoft Conversation Transcription Service.
[Accepted in ICASSP 2021] [code] [demo] [slides] [poster]
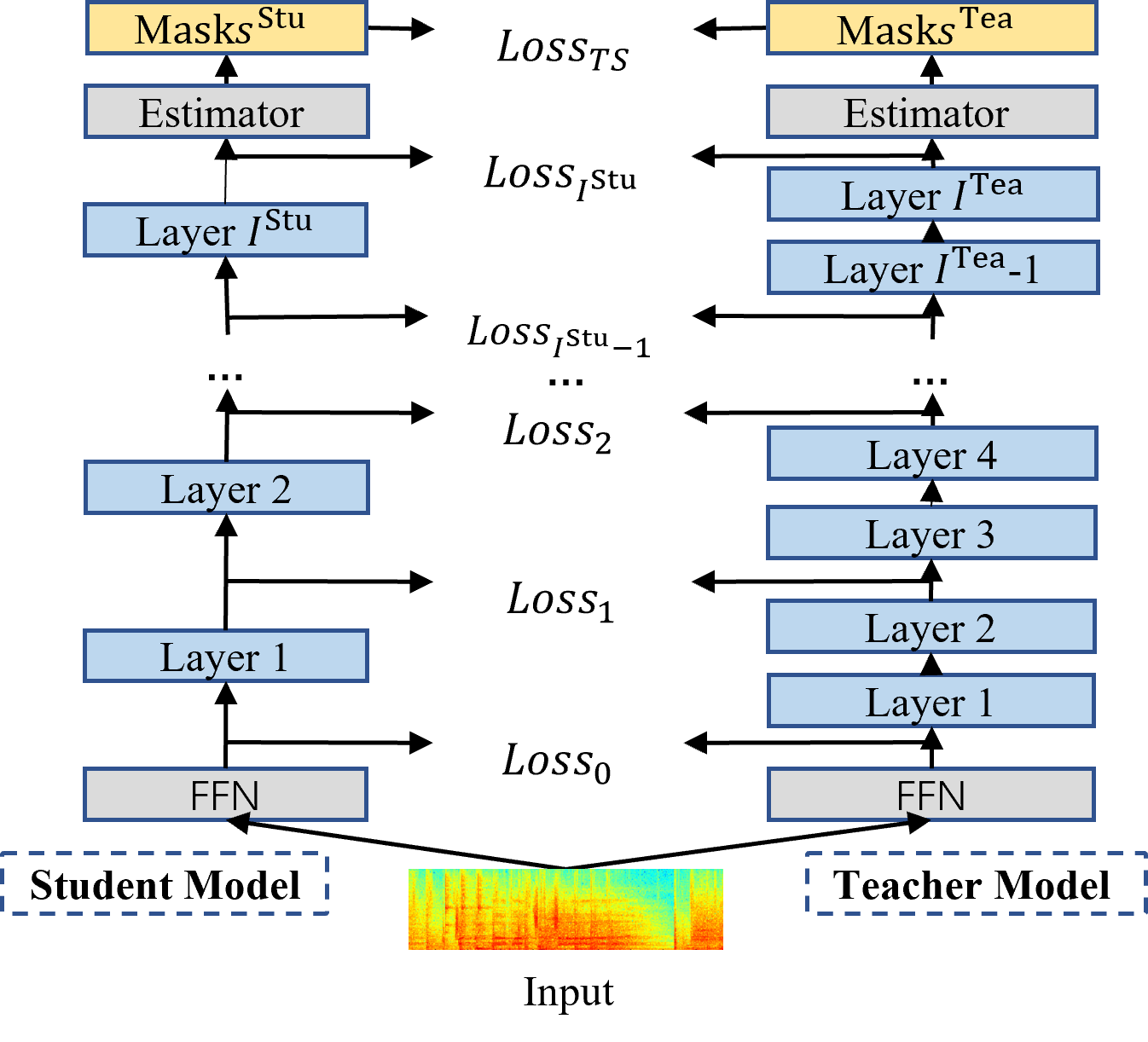
Ultra Fast Speech Separation Model with Teacher Student Learning
Sanyuan Chen, Yu Wu, Zhuo Chen, Jian Wu, Takuya Yoshioka, Shujie Liu, Jinyu Li, Xiangzhan Yu
Shipped in the Microsoft Conversation Transcription Service.
Don’t shoot butterfly with rifles: Multi-channel Continuous Speech Separation with Early Exit Transformer
Sanyuan Chen, Yu Wu, Zhuo Chen, Takuya Yoshioka, Shujie Liu, Jinyu Li, Xiangzhan Yu
[Accepted in ICASSP 2021] [code] [slides] [poster]
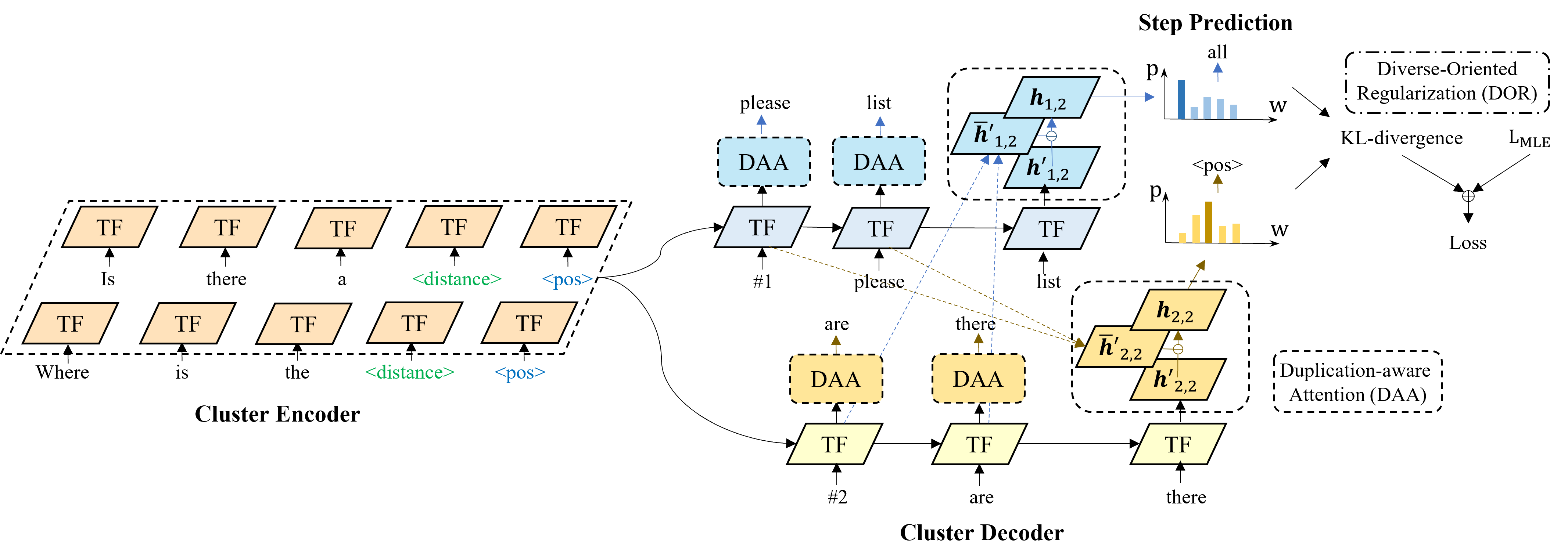
C2C-GenDA: Cluster-to-Cluster Generation for Data Augmentation of Slot Filling
Yutai Hou*, Sanyuan Chen*, Wanxiang Che, Cheng Chen, Ting Liu
[Accepted in AAAI 2021] [code] [video] [blog]

Recall and learn: Fine-tuning Deep Pretrained Language Models with Less Forgetting
Sanyuan Chen, Yutai Hou, Yiming Cui, Wanxiang Che, Ting Liu, Xiangzhan Yu
[Accepted in EMNLP 2020] [code] [video] [blog]